Before starting this #66daysofdata journey, I built a web scraper to extract award flight prices from NYC to Madrid. It got me interested in thinking about what next steps I could do with flight pricing data and led to me thinking about ways to explore predictive modeling. I found a great video online by Krish Naik that took a Kaggle dataset to predict flight prices so for the last 2 days I have been following along. Below is a breakdown of the steps but if you are interested I would follow the video for yourself.
Exploratory Data Analysis
As always the first thing to do is to explore our data as you can see below here are the first 10 rows.
As you can see, there are 11 columns. We want to predict ‘Price’ so we have 10 other potential columns of helpful information. What’s great is that we don’t have many Null values to deal with.
Data Cleaning
Now that we have a pretty good sense of what makes sense of this data we start to clean it up
Drop Null Values
The first thing we do is drop null values
Convert Date_of_Journey from string to useful columns
Break out month
Break out day
Drop Date_of_Journey – now that we broke it out we no longer need to have the original column
Feature Engineering
Additional_Info
We drop Additional_info as about 80% of the data is ‘No info’
Airline, Source, Destination
As I mentioned in my last post all of these fields are Nominal data, meaning there is no inherent order. Because of this, we use OneHotEncoder to create dummy variables, and to avoid the dummy variable trap we drop one column.
Feature Selection
After Feature Engineering we can look int Feature Importance. First, we check to see if there is any correlation between different variables. If we have a correlation value of 80%/ – 80% we should drop one column to avoid redundancy
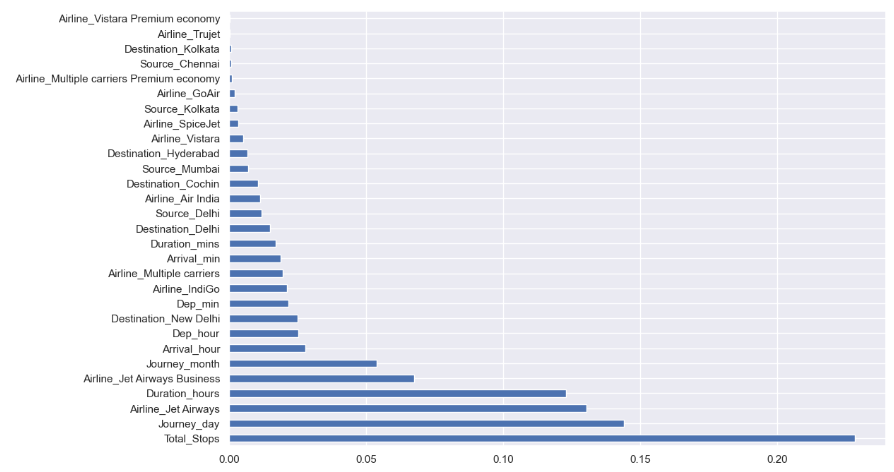
We then use ExtraTreeRegressor to see what are the most important features, as you can see below Total_Stops has the highest importance followed by Journey_Day, etc.
Fitting our Model
I’ll be honest and this is the part that I got lost in the most. We used Random Forest and got a score of .798 for our testing data set which isn’t the best
For Hyperparameter Tuning we used RandomizedSearchCV but this is where I got lost. Probably tomorrow will be into going over these different models and what each does.
Conclusion
Well, that’s it for this project thanks for following along on this journey of mine. Every project leads to new questions and tomorrow I’ll explore the differences between the different models I have used in this project and the first project I did. If you are interested in the looking at the notebook checkout the link to it in my GitHub.